Análisis de sentimientos con Python y Jupyter Notebooks
Hace algunos días presentamos en este mismo espacio la aplicación Jupyter Notebooks. Se trata de una herramienta muy interesante como entorno de ejecución de programas escritos en Python y otros lenguajes, muy usada en el ámbito de la investigación, el machine learning y la Inteligencia Artificial. En este artículo veremos un ejemplo para explicar cómo realizar el análisis de sentimientos en textos usando el lenguaje Python, la librería NLTK «Natural Language Toolkit» y la herramienta JupyterLab para desarrollar nuestro script en un Jupyter Notebook.
Instalar NLTK en Python
El primer paso será instalar la librería NLTK, para lo que usaremos el gestor de dependencias de Python Pip. Para instalar esta dependencia tenemos que abrir, dentro de JupyterLab, una nueva pestaña en la consola de Python, con la opción «File > New > Console».
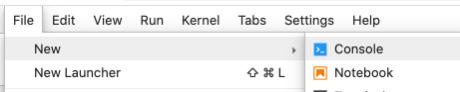
Ahora escribimos el comando necesario para realizar la instalación de la librería NLTK.
pip install --user nltk
Este comando instala la librería para el propio usuario sobre el que se ejecuta JupyterLab. Para ejecutarlo con el intérprete de Python en la consola hacemos «Run > Run selected cell».
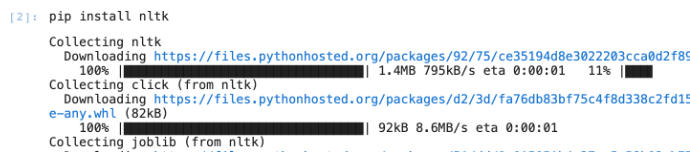
Una vez terminado el proceso, es necesario reiniciar el Kernel de Python, para lo que usamos la opción siguiente del menú: «Kernel > Restart kernel».
Realizar la instalación de los componentes necesarios de NLTK
Ahora ya podemos crear un nuevo Notebook donde realizaremos todo el trabajo para nuestra práctica. Para ello vamos a la opción «File > New > Notebook».
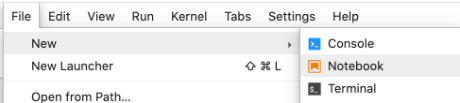
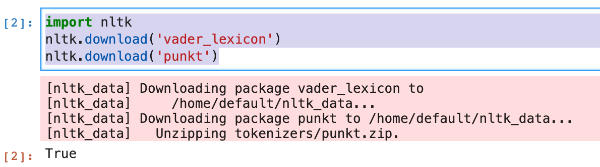
Para realizar el análisis de sentimientos en Python con NLTK vamos a usar dos componentes que tenemos que descargar convenientemente. Para ello, en la primera celda del notebook escribimos el siguiente código.
import nltk
nltk.download('vader_lexicon')
nltk.download('punkt')
Ejecutamos y obtendremos una salida como esta:
Dividir un texto en frases
A continuación vamos a trocear el texto a analizar mediante un proceso de tokenización que nos permite dividir las distintas frases de un párrafo, obteniendo cada una de ellas de manera separada. Esto se consigue muy fácilmente gracias a la librería nltk.
import nltk
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
sentences = tokenizer.tokenize('I am sure that is the reason why education is so important. When you are truly interested in something, you never stop learning. Later, do not stop to sharing knowledge with others.')
Ejecutado este script obtenemos una variable llamada «sentences» donde tendremos las tres frases de este texto, en distintas casillas de un array.
Analizar el sentimiento
Ahora nos toca sacarle partido a las herramientas de análisis de sentimiento de NLTK descargadas anteriormente, para lo cual vamos a examinar cada una de las frases por separado. Primero vamos a hacer todos los imports de los elementos que se van a usar.
from nltk.sentiment.vader import SentimentIntensityAnalyzer from nltk import sentiment from nltk import word_tokenize
Ahora crearemos el analizador de sentimientos.
analizador = SentimentIntensityAnalyzer()
Por último realizamos el análisis para cada una de las frases que habíamos obtenido anteriormente.
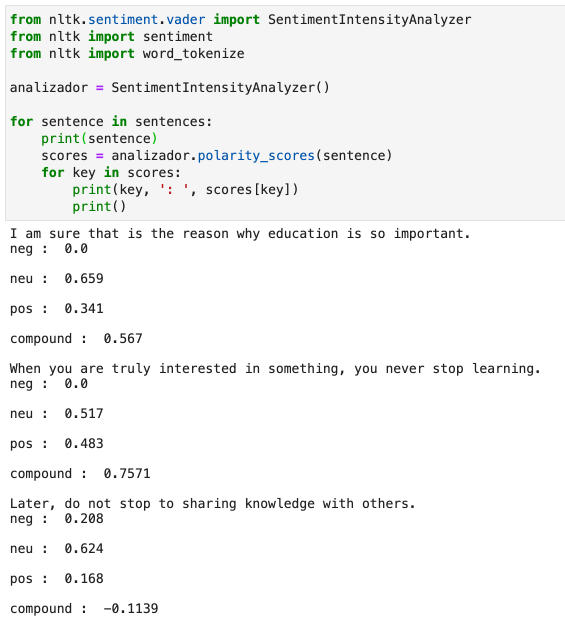
for sentence in sentences: print(sentence) scores = analizador.polarity_scores(sentence) for key in scores: print(key, ': ', scores[key]) print()
Para cada frase se obtienen varias puntuaciones diferentes, que podremos ver en la salida un poco más abajo. Pero antes resumimos los diversos criterios para las puntuaciones.
- neg (negativa): es un valor entre cero y uno, para decirnos lo negativa que sería esta frase.
- neu (neutral): este segundo valor nos indica la neutralidad de una frase, también en una puntuación entre cero y uno.
- pos (positiva): Igualmente que los anteriores, pero indicando lo positiva que encuentra una frase.
- compound: este es un valor entre -1 y 1 que viene a indicar de una única vez si la frase es positiva o negativa. Valores próximos a -1 indican que es muy negativa, próximos a cero indicarían que es neutra y próximos a 1 sería muy positiva. La salida para nuestro programa nos ofrecerá estas puntuaciones:
I am sure that is the reason why education is so important. neg : 0.0 neu : 0.659 pos : 0.341 compound : 0.567 When you are truly interested in something, you never stop learning. neg : 0.0 neu : 0.517 pos : 0.483 compound : 0.7571 Later, do not stop to sharing knowledge with others. neg : 0.208 neu : 0.624 pos : 0.168 compound : -0.1139
Nota: Como se puede apreciar, Vader nos ofrece el análisis de sentimientos de frases escritas en inglés, pero podríamos valernos de esta misma librería para textos en español si hacemos primero una traducción de los mismos a través de cualquier API de traducción automática.

Jefe de Capacitación para Soluciones Cloud, posee una amplia experiencia en áreas comerciales y técnicas a nivel nacional e internacional. Con una base en Ingeniería de Telecomunicaciones y un MBA, destaca en el desarrollo de negocios, especialmente con grandes cuentas y partners en sectores tanto privados como públicos.