¿Qué es Ollama y cómo integrarlo en n8n?
Si estás al día en el mundo de la IA sabrás que hay alternativas open source que puedes usar gratuitamente. En este sentido, Ollama se ha posicionado como una de las herramientas más potentes para trabajar con modelos de lenguaje de forma local, de manera gratuita y sin tener que conectarte a Internet, usando solamente la capacidad de procesamiento de tu ordenador. Si sumamos estas características a la versatilidad de n8n, podemos montar flujos de automatización con IA que son totalmente privados, rápidos y, sobre todo, gratuitos.
- ¿Qué es Ollama?
- Ventajas de usar Ollama frente a API externas
- Requisitos previos para ejecutar Ollama y n8n
- ¿Cómo integrar Ollama en n8n paso a paso?
- Casos de uso para automatizar con Ollama y n8n
- Optimización y rendimiento de la integración de Ollama en n8n
- Solución de problemas comunes
- Preguntas frecuentes sobre Ollama y n8n
¿Qué es Ollama?
Por si no lo conoces todavía, Ollama es un software que permite usar modelos de IA de una manera sencilla en local. En pocas palabras es una plataforma que te permite descargar y poner a funcionar modelos de lenguaje (LLM) directamente en tu propio ordenador o servidor.
Gracias a Ollama puedes usar los modelos en local, evitando transferir tus datos a un servidor. Ollama se encarga de las partes complejas y gestiona todo el proceso de montaje de esos modelos en tu ordenador, además de permitirte usarlos de manera sencilla. Es la alternativa perfecta para suplir funcionalidades que actualmente estás usando con OpenAI o Anthropic.
Con Ollama podrás usar modelos tan conocidos como Llama 3, Mistral, Gemma o Phi-2. Quizás no sean los más potentes a nivel de razonamiento pero son más que suficientes para hacer tareas del día a día. Solo tienes que elegir el modelo y acceder a ellos mediante una API local que es sencillísima de integrar con tus aplicaciones preferidas.
Ventajas de usar Ollama frente a API externas
Aunque podrías usar API externas de actores relevantes de IA, la verdad es que no es necesario para la mayoría de las tareas de automatización. De hecho, vamos a ver algunas ventajas de usar Ollama frente a servicios en la nube.
Eliminación de costes recurrentes y pago por uso de tokens
Lo más relevante para muchos es que te olvidas de los costes por uso. Cuando usas una API en la nube, pagas por cada token procesado y, aunque las cantidades no son muy grandes en muchos casos, con con Ollama es totalmente gratuito, ya que los modelos viven en tu equipo y usan tu propia capacidad de procesamiento.
Privacidad total: tus datos sensibles nunca salen de tu infraestructura
Pero aparte de los costes, en muchos casos también es importante pensar en la confidencialidad. Al usar Ollama todos tus datos se quedan en tu máquina o servidor, lo que es esencial para muchos tipos de negocios que usan información sensible o necesitan acogerse a unos niveles de privacidad elevados.
Ejecución 100% offline sin dependencia de conexión a Internet o servidores externos
También podemos destacar que no necesitas estar conectado a internet para que Ollama funcione (una vez hayas descargado el modelo, claro). Esto te vendrá genial si trabajas en entornos offline por las características de tu negocio.
Latencia reducida al eliminar el tiempo de respuesta de red
Al ejecutar el modelo localmente no necesitas que tu petición viaje hasta un servidor remoto y esperar a que vuelva la respuesta. Es decir, la latencia se elimina completamente, por lo que tus tareas pueden ser más rápidas de responderse, siempre que tu capacidad de procesamiento sea la suficiente.
Libertad total en la personalización y ajuste fino de los modelos de lenguaje
Por último, también queremos destacar la libertad que te da este enfoque, ya que puedes personalizar los modelos, crear tus propias variaciones y ajustar parámetros diversos. Incluso Ollama nos permite extender los modelos locales para que se adapten exactamente a lo que necesitamos.
Requisitos previos para ejecutar Ollama y n8n
Vamos a ver qué necesitas para conseguir ejecutar Ollama en tu ordenador, así como el sistema de automatización n8n.
Hardware recomendado
Lo primero que debes asegurarte de disponer de un hardware suficientemente potente para que la experiencia sea fluida. En concreto te recomendamos contar con estos recursos por lo menos:
- Una CPU con varios núcleos.
- Mínimo 16 GB de RAM.
- Una GPU compatible.
Algunos modelos funcionan bien solamente con CPU pero si quieres que la IA te responda rápidamente es importante que tengas una tarjeta gráfica adecuada.
Instalación de Ollama en Windows, macOS y Linux
Instalar Ollama en cualquier sistema es bien sencillo. Si estás en Windows o MacOS tienes la posibilidad de descargar el instalador desde la sección de download.
Ya si estás en Linux encontrarás un comando para que se descargue y se instale Ollama.
curl -fsSL https://ollama.com/install.sh | sh
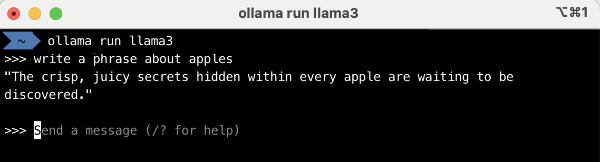
Una vez lo tengas instalado, si es que lo has descargado con el instalador, necesitas abrir el programa y se cargará el comando ollama en tu ordenador. Ya solo queda arrancar el sistema lanzando este comando en tu consola:
ollama run llama3
Verás cómo comienza la descarga del modelo seleccionado, en este caso Llama 3, y en pocos minutos podrás comenzar a trabajar directamente con él.
Configuración de n8n para comunicación local
El siguiente paso es integrar Ollama con n8n. Para empezar tienes que instalarlo en tu sistema. Para resolver este paso te recomendamos leer la Guía completa de n8n que hemos publicado en nuestro blog.
De todos modos, solo para adelantarnos a tu consulta, lo más típico y sencillo es usar Docker para poner en funcionamiento n8n en un ordenador o un servidor. Lo haces con este comando de terminal:
docker volume create n8n_data docker run -it --rm \ --name n8n \ -p 5678:5678 \ -e GENERIC_TIMEZONE='Europe/Madrid' \ -e TZ='Europe/Madrid' \ -e N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true \ -e N8N_RUNNERS_ENABLED=true \ -v n8n_data:/home/node/.n8n \ docker.n8n.io/n8nio/n8n
Solo ten en cuenta que posiblemente tengas que personalizar el timezone a tu región en particular.
¿Cómo integrar Ollama en n8n paso a paso?
Para integrar Ollama con n8n tenemos que realizar unas pequeñas configuraciones que vamos a resumir ahora para que no te pierdas.
Configuración de la variable de entorno OLLAMA_HOST para acceso externo
Si tienes n8n y Ollama en sitios distintos (por ejemplo, si usas n8n dentro de un contenedor Docker), tendrás que decirle a Ollama que acepte conexiones que vienen desde fuera. Lo más directo es configurar esta variable de entorno:
export OLLAMA_HOST=0.0.0.0
Ese comando hará que la variable de entorno OLLAMA_HOST se setee con 0.0.0.0, lo que significa que se puede iniciar el servicio de Ollama desde todas las interfaces de red, como desde un contenedor Docker donde se ejecuta n8n.
Eso servirá para la sesión de terminal actual, por lo que si quieres que sea permanente tendrás que configurarlo en tu shell, cuyos pasos pueden depender el tipo de shell que uses y el sistema operativo que tengas. En Windows ten en cuenta que necesitarás activar la variable de entorno en la ventana de configuración de variables de entorno que ofrece el sistema operativo.
Uso del nodo Ollama nativo en n8n
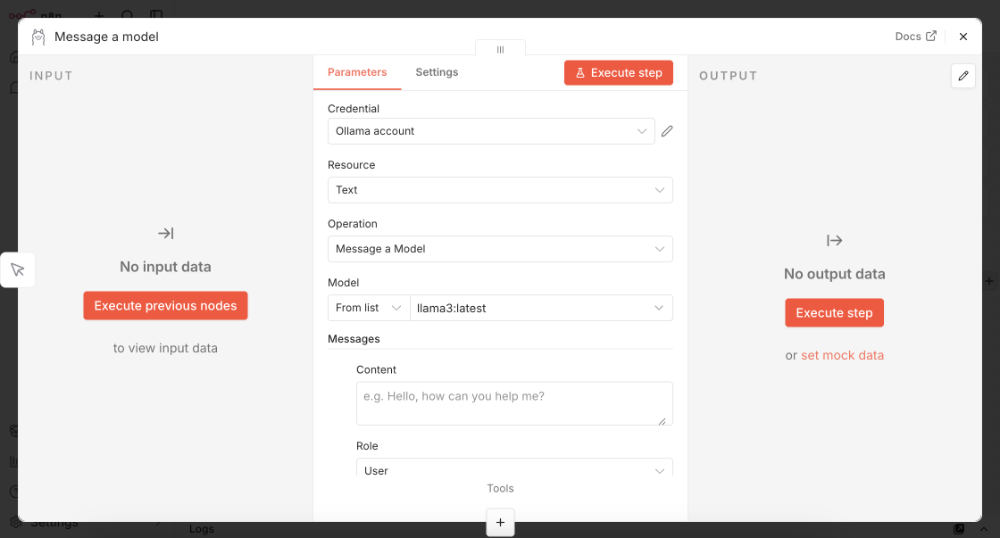
La integración de n8n con Ollama es bastante directa ya que n8n incluye un nodo nativo para Ollama. Simplemente tendremos que crear el nodo en nuestro workflow y encontraremos la opción de usar Ollama. El procedimiento se hace tan sencillo como escoger un nodo de IA.
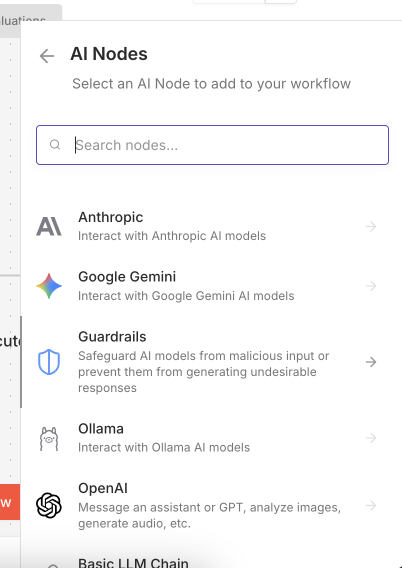
Entonces seleccionas Ollama y verás una ventana de configuración donde podrás enviar tus prompts, usando también la salida de nodos anteriores, y recibir las respuestas de la IA directamente como datos dentro de nuestro flujo de trabajo.
De todos modos, para conseguir que Ollama funcione necesitas hacer algunos pasos extra, como la configuración de credenciales.
Configuración de credenciales y conexión al endpoint local
Como decimos, para poder usar Ollama será necesario crear las correspondientes credenciales, aunque el modelo lo tengas en local.
Desde el navegador en el panel de n8n localiza el botón «+» en la parte superior y añade las credenciales. Tendrás que seleccionar Ollama.
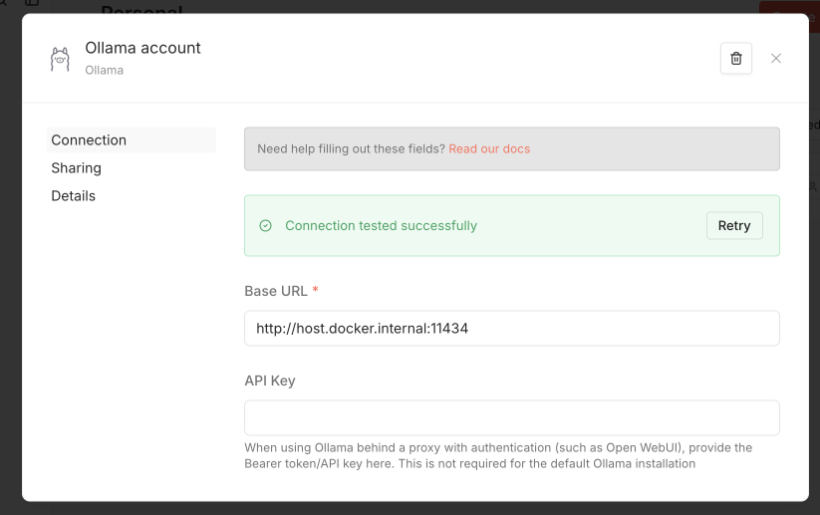
En la ventana de añadir credencial solo tendrás que indicar el host, que si has configurado n8n dentro de Docker será como este https://host.docker.internal:11434.
Si no estás en Docker, entonces usarás simplemente https://localhost:11434.
Los parámetros de autenticación no te hará falta tocarlos, ya que estás en un entorno local donde no necesitas llaves de API .
Selección del modelo y ajuste de parámetros
A la hora de configurar tu nodo en el workflow podrás configurar la llamada a Ollama en el formulario.
Entre otras cosas podrás elegir el modelo que quieras usar (como «llama3» o «mistral», que lógicamente tendrás que haber descargado antes en Ollama). Luego podrás ajustar los parámetros de uso del modelo a tu gusto.
A partir de aquí, el límite es tu imaginación: puedes usar la IA para resumir textos, clasificar correos o generar contenido para los siguientes pasos del flujo de trabajo.
Casos de uso para automatizar con Ollama y n8n
La integración de Ollama en n8n nos abre un mundo de posibilidades enorme. De hecho, si n8n ya nos ofrece la posibilidad de montar automatizaciones potentes, manteniendo todo el control en nuestra propia infraestructura, si le unimos la IA todavía podemos llegar más lejos. Aquí puedes ver algunas ideas variadas.
Clasificación automática de correos electrónicos con IA privada
Cuando la bandeja de entrada de tu correo crece y crece sin control puedes aplicar automatizaciones combinadas con IA para clasificar los mensajes. Pues bien, podemos conectar n8n a vuestra cuenta de correo y dejar que Ollama lea y analice cada mensaje por nosotros, tomando decisiones que nos ayuden a mejorar el soporte.
Gracias a la IA se puede usar el cuerpo del correo para clasificarlo por categorías o prioridad, sin que ningún dato salga de vuestro servidor, lo que puede ser importante para casos donde se deba mantener niveles de privacidad elevados.
Resumen de documentos PDF y extracción de datos estructurados (JSON)
Procesar documentos como facturas o informes largos puede ser una tarea pesada y tediosa. Lo bueno es que con n8n podemos automatizarla y extraer la información que nos interesa.
Por ejemplo podrías leer el texto de un PDF y resumirlo o que nos devuelva los datos importantes en un JSON. Por ejemplo, podrías sacar los valores de los importes de las facturas, las fechas o cualquier otra información para contabilizarla.
Creación de un chatbot de soporte técnico 100% offline
Usando Ollama podríamos crear un chatbot totalmente gratuito que funciona 100% offline. Si lo combinas con un flujo de n8n y una interfaz sencilla puedes hacer que funcione de una manera muy profesional, por ejemplo para ofrecer una solución de asistencia en las redes corporativas, manteniendo no solo la autonomía, sino también la seguridad y la privacidad.
Análisis de sentimiento en redes sociales sin enviar datos a la nube
Si queremos saber qué se dice de nosotros (o de nuestros competidores) en redes sociales, n8n puede capturar cualquier comentario o referencia y luego, gracias a Ollama, lo puedes analizar para saber si el tono es positivo o negativo. Así, obtenemos informes detallados sin tener que usar servicios externos.
Optimización y rendimiento de la integración de Ollama en n8n
Ahora vamos a ver cómo podemos hacer que nuestros flujos funcionen de manera ágil, aprovechando el rendimiento de las infraestructuras.
Cómo gestionar la latencia de respuesta en modelos locales
Si bien es cierto que al trabajar en local eliminamos los retrasos de la red, también es importante saber que existirá un tiempo de respuesta que dependerá de la máquina y los recursos de hardware que disponga.
Entonces, para que no se os haga eterna la espera, podemos tomar algunas consideraciones:
- Usar ordenadores o servidores con suficiente hardware.
- Mantener cargados solo los modelos que vayas a usar.
- Cuidar los prompts, de modo que sean claros pero directos y concisos.
- No usar el servidor para otras tareas al mismo tiempo.
Uso de modelos cuantizados para ahorrar recursos de sistema
Dependiendo de la tarea que vayas a realizar te interesará usar un modelo u otro. Aparte de las características de cada modelo también debes tener en cuenta que puedes usar versiones «cuantizadas». Estas son como versiones comprimidas que consumen mucha menos memoria RAM del sistema, a causa de ser un poco menos precisas.
Para la mayoría de las tareas ni se percibe ese menor nivel de precisión derivado del uso de versiones cuantizadas, pero muchas veces la diferencia de velocidad sí es bastante perceptible, sobre todo si no tienes un superordenador.
Orquestación de múltiples modelos según la complejidad de la tarea
Otra cosa importante: no solo necesitas usar un tipo de modelo, en realidad puedes combinarlos en un mismo flujo, dependiendo de la complejidad de cada solicitud en ese nodo en particular.
Existen modelos pequeños como Phi o TinyLlama que puedes usar para clasificaciones rápidas o tareas muy simples, mientras que otros tipos de modelos como Mistral, Gemma puedes usarlos para análisis estándar. Los modelos más grandes, como Llama 3 los puedes dejar para los casos en los que necesites razonamientos complejos o respuestas muy elaboradas.
Solución de problemas comunes
Si te animas a usar Ollama en los flujos de n8n verás que en realidad es bastante sencillo sacarle partido a la IA. Sin embargo, la tarea no está exenta de dificultades, algunas de las cuales te vamos a adelantar por si tienes problemas con ellas.
Error de conexión entre n8n y Ollama
Si tienes fallos de conexión entre los sistemas verás que el nodo se pone rojo. Si ocurre eso lo primero es comprobar que Ollama está realmente corriendo en el sistema.
Si usas Docker, recuerda que la dirección suele ser host.docker.internal para que el contenedor pueda ver lo que pasa fuera.
Problemas de velocidad
A veces puedes sentir que la IA tarda demasiado en contestar. Si es así, echa un ojo al consumo de recursos en el equipo, y especialmente a la RAM.
Si vais justos, probad con las versiones cuantizadas que a veces ayudan bastante, sobre todo en equipos más modestos. También ayuda mucho no construir prompts demasiado largos, si no son necesarios.
Errores al cargar modelos específicos en entornos Docker
A veces Docker se pone un poco estricto con los permisos o la memoria y nos puede dar errores. Si es el caso toma en consideración la asignación de memoria suficiente al contenedor. Además, recomendamos montar los modelos en un directorio como volumen persistente, para que no tenga que descargarlo todo cada vez.
Preguntas frecuentes sobre Ollama y n8n
Ya para acabar vamos a ver algunas dudas frecuentes que pueden surgir cuando estás comenzando con Ollama y n8n.
¿Es gratis usar Ollama con n8n de por vida?
Sí, Ollama es completamente gratuito. No tienes que preocuparte por los gastos. Solamente por hacerte con un hardware suficiente y pagar la factura de la luz!!
Eso sí, ten en cuenta que puede que haya algunas licencias de modelos que no permitan el uso en acciones comerciales.
¿Puedo usar Ollama en un servidor VPS?
Puedes perfectamente, pero ten en cuenta la potencia de la máquina. Para que Ollama funcione como esperas lo ideal sería que el VPS tenga una GPU o, al menos, una buena cantidad de RAM.
¿Cómo actualizar los modelos de Ollama desde n8n?
Esto generalmente lo harás a mano con los propios comandos de consola (ollama pull). Pero en la práctica también podrías montar un flujo en n8n que de vez en cuando ejecute ese comando para asegurarte de que estás usando la última versión del modelo.
¿Es compatible Ollama con LangChain dentro de n8n?
Sí. De hecho, si quieres llevar tus automatizaciones al siguiente nivel con agentes o memoria a largo plazo, puedes usar LangChain dentro de n8n usando a Ollama como el motor de IA que se encarga de orquestar todo.

Desarrollador web, crea y mantiene los sitios web de Arsys. También idea herramientas internas que facilitan y mejoran los procesos. Es experto en desarrollo FrontEnd y en la optimización del rendimiento web, áreas en las que constantemente busca innovar para ofrecer la mejor experiencia online.